배열
1. 배열
기본적으로 자바스크립트의 배열은 객체타입으로 여러가지 프로퍼티를 가지고 있다. 가장 대표적인 프로퍼티가 length이다.
const arr = [1, 2, 3];
for (let i = 0; i < arr.length; i++) {
console.log(arr[i]); // 1 2 3
}
배열은 객체로, Array 생성자 함수를 가지고 있다. 때문에 프로토타입도 Array.prototype을 갖는다.
const arr = [1, 2, 3];
console.log(arr.constructor === Array); // true
console.log(Object.getPrototypeOf(arr) === Array.prototype); // true
1.1 희소 배열
- 자바스크립트의 배열은 일반적인 배열과는 다르다.
- 일반적인 배열: 동일한 크기의 메모리 공간이 빈틈없이 연속적으로 나열된 자료구조.
- 밀집 배열( dense array )
- 즉, 배열의 요소는 하나의 데이터 타입으로 통일되어 있으며, 서로 연속적으로 인접해있음.
- 자바스크립트의 배열: 희소 배열( sparse array)
- 요소를 위한 각각의 메모리 공간이 동일한 크기를 갖지 않아도 되며,
- 연속적으로 이어져 있지 않을 수도 있음.
- 배열의 요소가 연속적으로 이어져 있지 않는 배열.
즉, 자바스크립트의 배열은 일반적인 배열의 동작을 흉내낸 특수한 객체.
const arr = [1, 2, 3];
console.log(Object.getOwnPropertyDescriptors(arr));
/*
{
'0': { value: 1, writable: true, enumerable: true, configurable: true },
'1': { value: 2, writable: true, enumerable: true, configurable: true },
'2': { value: 3, writable: true, enumerable: true, configurable: true },
length: { value: 3, writable: true, enumerable: false, configurable: false }
}
*/
- 자바스크립트의 배열은 인덱스를 나타내는 문자열을 프로퍼티 키로 가짐. length 프로퍼티를 갖는 특수한 객체일 뿐이다.
- 자바스크립트의 배열 요소: 프로퍼티의 값
- 자바스크립에서 사용할 수 있는 모든 값은 객체의 프로퍼티 값이 될 수 있으므로 어떤 타입의 값이라도 배열의 요소가 될 수 있다.
const arr = [
"string",
10,
true,
null,
undefined,
NaN,
Infinity,
[],
{},
function () {},
];
- 자바스크립트 배열⇒ 해시 테이블로 구현된 객체이므로, 인덱스로 요소에 접근하는 경우? 일반적인 배열보다 느릴 수 밖에 없다. 하지만 특정 요소를 삽입, 삭제하는 경우? 일반적인 배열보다 빠른 성능을 기대할 수 있음. 또한, 최신 엔진에서는 배열의 성능을 최적화하였기 때문에 객체로 직접 만든 배열보다, 2배 더 빠른 속도를 가지게 됨.
1.2 length 프로퍼티와 희소 배열
length 프로퍼티: 요소의 개수
- 0이상 2^32-1( 4,294,967,276 - 1) 미만의 양의 정수.
- 현재 length 프로퍼티 값보다 작은 숫자 값을 할당하면 배열의 길이가 줄어듬
const arr = [1, 2, 3, 4, 5];
arr.length = 3;
console.log(arr); // [ 1, 2, 3 ]
이를 이용하여 length를 0으로 바꾸면 깔끔하게 배열을 비울 수 있음.
const arr = [1, 2, 3, 4, 5];
arr.length = 0;
console.log(arr); // []
반대로, 원소의 개수보다 length 길이를 크게해도 달라지는 것은 없음.
const arr = [1, 2, 3, 4, 5];
arr.length = 100;
console.log(arr); // [ 1, 2, 3, 4, 5, <95 empty items> ]
요소가 없는 부분을 empty items라고 표현하였는데,
그렇다고 값이 비어있는 요소를 위해 메모리 공간을 확보하지 않으며 빈 요소를 생성하지도 않는다.
const arr = [, 2, , 4];
arr.length = 10;
console.log(Object.getOwnPropertyDescriptors(arr));
/*
{
'1': { value: 2, writable: true, enumerable: true, configurable: true },
'3': { value: 4, writable: true, enumerable: true, configurable: true },
length: { value: 10, writable: true, enumerable: false, configurable: false }
}
*/
- 희소 배열 : 현재 배열의 요소가 연속적으로 위치하지 않고, 일부가 비어 있는 배열
- 자바스크립트는 희소 배열을 문법적으로 허용
- 희소 배열은 length와 배열 요소의 개수가 불일치. 희소 배열의 length는 희소 배열의 실제 요소 개수보다 언제나 크다.
- 일반적인 배열은 length는 배열 요소의 개수, 즉 배열의 길이와 언제나 일치.
1.3 배열 생성
1.3.1 배열 리터럴
배열 리터럴로 [] 안에 0개 이상의 요소를 넣어서 생성.
const arr = [1, 2, 3];
const arr2 = [];
console.log(arr); // [ 1, 2, 3 ]
console.log(arr2); // []
1.3.2 Array 생성자 함수
- 주의!! Array 생성자 함수는 전달된 인수의 개수에 따라 다르게 동작
- 전달된 인수가 1개이고, 숫자인 경우 ⇒ length 프로퍼티 값이 인수인 배열을 생성
const arr = new Array(10);
console.log(arr);
// [ <10 empty items> ]
//희소배열
// length 프로퍼티 값은 0이 아니지만 실제로 배열의 요소는 존재하지 않는다.
console.log(arr.length); // 10
- 전달된 인수가 0개인 경우 ⇒ 빈 배열을 생성
const arr = new Array();
console.log(arr); // []
console.log(arr.length); // 0
- 전달된 인수가 2개 이상이거나 숫자가 아닌 경우 ⇒ 인수를 요소로 갖는 배열을 생성
const arr = new Array(1, 2, 3);
console.log(arr); // [ 1, 2, 3 ]
- Array 생성자 함수는 new 연산자와 함께 호출하지 않더라도, 일반 함수로서 호출해도 배열을 생성하는 생성자 함수로 동작한다. Array 생성자 함수 내부에서 new.target을 확인하기 때문
1.3.3 Array.of
- ES6에서 도입된
Array.of메서드 - 전달된 인수를 요소로 갖는 배열을 생성.
Array.of는 Array 생성자 함수와 다르게 전달된 인수가 1개이고 숫자이더라도 인수를 요소로 갖는 배열을 생성한다.
console.log(Array.of(1)); // [ 1 ]
console.log(Array.of(1, 2, 3)); // [ 1, 2, 3 ]
console.log(Array.of("string")); // [ 'string' ]
1.3.4 Array.from
- ES6에서 도입된
Array.from메서드 - 유사 배열 객체 또는 이터러블 객체를 인수로 전달받아 배열로 변환하여 반환한다.
const arr = Array.from({ length: 2, 0: "a", 1: "b" }); // 유사 배열 객체를 변환하여 배열로 만든다.
const helloArray = Array.from("hello"); // 이터러블을 변환하여 배열을 생성한다. 문자열은 이터러블이다.
console.log(arr); // [ 'a', 'b' ]
console.log(helloArray); // [ 'h', 'e', 'l', 'l', 'o' ]
- 두 번째 인수로 전달한 콜백 함수에 첫 번째 인수에 의해 생성된 배열의 요소값과 인덱스를 순차적으로 전달하면서 호출, 콜백 함수의 반환값으로 구성된 배열을 반환.
console.log(Array.from({ length: 3 })); // [ undefined, undefined, undefined ]
console.log(Array.from({ length: 3 }, (_, i) => i)); // [0, 1, 2]
- 유사 배열 객체와 이터러블 객체유사 배열 객체?? : 마치 배열처럼 인덱스로 프로퍼티 값에 접근할 수 있고, length 프로퍼티를 갖는 객체. 유사 배열 객체는 마치 배열처럼 for문으로 순회가 가능.
const arrayLike = {
0: "apple",
1: "banana",
2: "orange",
length: 3,
};
for (let i = 0; i < arrayLike.length; i++) {
console.log(arrayLike[i]); // apple, banana, orange
}
이터러블 객체
: Symbol.iterator 메서드를 구현하여 for ... of 문으로 순회할 수 있으며,
스프레드 문법과 배열 디스트럭처링 할당의 대상으로 사용할 수 있는 객체.
ES6에서 제공하는 빌트인 이터러블은 Array , String , Map, Set , DOM컬렉션( NodeList, HTMLCollection), arguments 등
1.4 배열 요소의 추가와 갱신
배열은 객체로 희소 배열이다. 따라서 인덱스는 프로퍼티가 된다.
const arr = [];
//배열 요소 추가
arr[0] = 1;
arr["1"] = 2;
//프로퍼티 추가
arr["foo"] = 3;
arr.bar = 4;
arr[1.1] = 5;
arr[-1] = 6;
console.log(arr); // [ 1, 2, foo: 3, bar: 4, '1.1': 5, '-1': 6 ]
//프로퍼티는 length에 영향을 주지 않는다.
console.log(arr.length); // 2
1.5 배열 요소의 삭제
배열은 사실 객체이기 때문에 배열의 특정 요소를 삭제하기 위해 delete 연산자 사용가능.
const arr = [1, 2, 3];
delete arr[1]; // arr에서 프로퍼티 키가 '1'인 프로퍼티를 삭제
console.log(arr); // [ 1, <1 empty item>, 3 ]
// length 프로퍼티에 영향을 주지 않는다. 즉 희소 배열이 된다.
// 따라서 희소 배열을 만드는 delete 연산자는 사용하지 않는 것이 좋다.
console.log(arr.length); // 3
console.log(arr[1]); // undefined
- delete 연산자
- 객체의 프로퍼티를 삭제.
- 희소 배열을 만드는 delete 연산자는 사용하지 않는 것이 좋다.
- 희소 배열을 만들지 않으면서 배열의 특정 요소를 완전히 삭제?
Array.prototype.splice메서드를 사용 - splice(시작 인덱스, 개수)
const arr = [1, 2, 3];
// arr[1]부터 1개의 요소를 제거한다.
arr.splice(1, 1);
console.log(arr); // [1,3]
// length가 자동 갱신된다.
console.log(arr.length); // 2
2. 배열 메서드
Array 생성자 함수는 정적 메서드를 제공
배열 객체의 프로토타입인 Array.prototype은 프로토타입 메서드를 제공
배열 메서드는 결과물을 반환하는 패턴이 두 가지이므로 주의가 필요하다.| 배열에는
- 원본 배열(배열 메서드를 호출한 배열, 즉 배열 메서드의 구현체 내부에서 this가 가리키는 객체)을 직접 변경하는 메서드와
- 원본 배열을 직접 변경하지 않고 새로운 배열을 생성하여 반환하는 메서드가 있다.
const arr = [1];
arr.push(2); // push 메서드는 원본 배열을 직접 변경했다.
console.log(arr); // [1,2]
const result = arr.concat(3); // concat 메서드는 원본 배열을 직접 변경하지 않고 새로운 배열을 생성하여 반환한다.
console.log(result); // [ 1, 2, 3 ]
- 원본 배열을 직접 변경하는 메서드는 외부 상태를 직접 변경하는 부수 효과가 있으므로 사용할 때 주의. 따라서 가급적 원본 배열을 직접 변경하지 않는 메서드를 사용하는 편이 좋다.
- push, pop, splice vs. [...], concat, slice
2.1 Array.isArray
- Arrray 생성자 함수의 정적 메서드
- 메서드 인수가 배열이면 true,아니면 false이다.
console.log(Array.isArray([])); // true
console.log(Array.isArray([1, 2])); // true
console.log(Array.isArray(new Array())); // true
console.log(Array.isArray()); // false
console.log(Array.isArray({})); // false
console.log(Array.isArray(null)); // false
console.log(Array.isArray({ 0: 1, length: 1 })); // false
2.2 Array.prototype.indexOf
- 원본 배열에서 인수로 전달된 요소를 검색하여 인덱스를 반환.
- 만약 원본 배열에 인수로 전달한 요소와 중복되는 요소가 여러 개 있다면 첫 번째로 검색된 요소의 인덱스를 반환.
- 만약 없다면 -1을 반환.
const arr = [1, 2, 2, 3];
//배열 arr에서 요소 2를 검색하여 첫 번째로 검색된 요소의 인덱스를 반환한다.
console.log(arr.indexOf(1)); // 1
//배열 arr에 요소 4가 없으므로 -1을 반환한다.
console.log(arr.indexOf(4)); // -1
//두번째 인수는 검색을 시작할 인덱스다. 두 번째 인수를 생략하면 처음부터 검색한다.
console.log(arr.indexOf(2, 2)); // 2
보통 indexOf()을 통해서 어떤 값이 배열에 있는지 없는지 확인하기 위해서 사용하는데,
ES7에서 도입된 Array.prototype.includes 메서드를 사용하면 가독성이 더 좋음
const arr = [1, 2, 2, 3];
//배열 arr에서 요소 2를 검색하여 첫 번째로 검색된 요소의 인덱스를 반환한다.
console.log(arr.indexOf(1)); // 1
//배열 arr에 요소 4가 없으므로 -1을 반환한다.
console.log(arr.indexOf(4)); // -1
console.log(arr.includes(2)); // true
2.3 Array.prototype.push
- 인수로 전달받은 모든 값을 원본 배열의 마지막 요소로 추가하고 변경된 length 프로퍼티 값을 반환
const arr = [1, 2];
let result = arr.push(3, 4);
console.log(arr); // [ 1, 2, 3, 4 ]
console.log(arr.length); // 4
- 성능 면에서 좋지 않다. 마지막 요소로 추가할 요소가 하나뿐이라면?? length 프로퍼티를 사용하여 배열 마지막 요소에 직접 추가. 이 방법이 push 메서드보다 빠름. 또한 length도 자동으로 추가됨.
const arr = [1, 2];
arr[arr.length] = 3;
console.log(arr); // [ 1, 2, 3 ]
arr[arr.length] = 5;
arr[arr.length] = 5;
arr[arr.length] = 5;
arr[arr.length] = 5;
console.log(arr); // [1, 2, 3, 5, 5, 5, 5]
console.log(arr.length); // 7
- push 메서드는 원본 배열을 직접 변경하는 부수 효과가 있어 스프레드 문법을 사용하는 것이 좋다.
const arr = [1, 2];
const newArr = [...arr, 3];
console.log(newArr); // [ 1, 2, 3 ]
2.4 Array.prototype.pop
- 원본 배열에서 마지막 요소를 제거하고 제거한 요소를 반환.
- 원본 배열이 빈 배열이면 undefined를 반환.
- pop 메서드는 원본 배열을 직접 변경한다.
const arr = [1, 2];
//원본 배열에서 마지막 요소를 제거하고 제거한 요소를 반환한다.
let result = arr.pop();
console.log(result); // 2
console.log(arr); // [ 1 ]
- pop 메서드와 push 메서드를 이용하여 스택 또한 쉽게 구현할 수 있음.
2.5 Array.prototype.unshift
- 인수로 전달받은 모든 값을 배열의 선두에 요소로 추가하고 변경된 length 프로퍼티를 반환
- 원본 배열을 직접 변경하는 부수 효과가 있다.
const arr = [1, 2];
//인수로 전달받은 모든 값을 배열의 선두에 요소로 추가하고 변경된 length 값을 반환한다.
let result = arr.unshift(3, 4);
console.log(result); // 4
//unshift 메서드는 원본 배열을 직접 변경한다.
console.log(arr); // [ 3, 4, 1, 2 ]
- 스프레드 문법을 사용여 함수 호출 없이 표현식으로 선두에 요소를 추가할 수 있으며 부수 효과도 없다.
const arr = [1, 2];
const newArr = [3, ...arr];
console.log(newArr); // [ 3, 1, 2 ]
2.6 Array.prototype.shift
- 원본 배열에서 첫 번째 요소를 제거하고 제거한 요소를 반환.
- 원본 배열이 빈 배열이면 undefined를 반환.
- shift 메서드는 원본 배열을 직접 변경한다.
const arr = [1, 2, 10, 29];
let result = arr.shift();
console.log(result); // 1
console.log(arr); // [ 2, 10, 29 ]
- shift메서드와 push 메서드를 이용하여 큐를 구현할 수 있다.
2.7 Array.prototype.concat
- 인수로 전달된 값들(배열 또는 원시값)을 원본 배열 마지막 요소로 추가한 새로운 배열을 반환
- 인수로 전달한 값이 배열인 경우?? 배열을 해체하여 새로운 배열의 요소로 추가 ⇒ 원본 배열이 변경되지 않음
const arr1 = [1, 2];
const arr2 = [3, 4];
//arr1의 마지막에 arr2를 추가한다.
let result = arr1.concat(arr2);
console.log(result); // [ 1, 2, 3, 4 ]
//arr1의 마지막에 3을 추가한다.
result = arr1.concat(3);
console.log(result); // [ 1, 2, 3 ]
//arr1와 arr2를 잇고, 마지막에 5를 추가한다.
result = arr1.concat(arr2, 5);
console.log(result); // [ 1, 2, 3, 4, 5 ]
// 원본 배열은 변경되지 않는다.
console.log(arr1); // [ 1, 2 ]
- push와 unshift 메서드는 concat 메서드로 대체할 수 있다.
- push와 unshift 메서드는 원본 배열을 직접 변경하지만 concat 메서드는 원본 배열을 변경하지 않고 새로운 배열을 반환한다. ⇒ 따라서 push와 unshift 메서드를 사용할 경우 원본 배열을 반드시 변수에 저장해두어야 하며 concat 메서드를 사용할 경우 반환값을 반드시 변수에 할당 받아야 한다.
- concat 메서드는 ES6의 스프레드 문법으로 대체할 수 있다.
let result = [1, 2].concat([3, 4]);
console.log(result); // [ 1, 2, 3, 4 ]
result = [...[1, 2], ...[3, 4]];
console.log(result); // [ 1, 2, 3, 4 ]
- push/unshift 메서드와 concat 메서드를 사용하는 대신 ES6 스프레드 문법을 일관성 있게 사용하는 것을 권장.
2.8 Array.prototype.splice
- 원본 배열의 중간에 요소를 추가하거나, 중간에 있는 요소를 제거
- splice 메서드는 3개의 매개변수
- 원본 배열을 직접 변경한다.
arr.splice(start, count, items);
// start부터 count개 만큼 원소를 삭제하고, items 요소 목록을 추가
const arr = [1, 2, 3, 4];
//원본 배열의 인덱스 1부터 2개의 요소를 제거하고 그 자리에 새로운 요소 20, 30을 삽입한다.
const result = arr.splice(1, 2, 20, 30);
//제거한 요소가 배열로 반환된다.
console.log(result); // [ 2, 3 ]
// splice 메서드는 원본 배열을 직접 변경한다.
console.log(arr); // [ 1, 20, 30, 4 ]
const arr = [1, 2, 3, 4];
const result = arr.splice(1, 0, 20, 30);
//만약 두 번째 count 매개변수를 0으로 두면 아무것도 삭제하지 않고, 원소를 추가한다.
console.log(arr); // [ 1, 20, 30, 2, 3, 4 ]
const arr = [1, 2, 3, 4];
const result = arr.splice(1, 2);
//만약 추가할 요소들인 items를 넣지 않으면 삭제만.
console.log(arr); // [ 1, 4 ]
const arr = [1, 2, 3, 4];
const result = arr.splice(1);
//splice 메서드의 두 번째 인수, 즉 제거할 요소의 개수를 생략
// 첫 번째 인수로 전달된 시작 인덱스부터 모든 요소를 제거한다.
console.log(arr); // [ 1 ]
console.log(result); // [ 2, 3, 4 ]
2.9 Array.prototype.slice
- 인수로 전달된 범위의 요소들을 복사하여 배열로 반환
- 원본 배열은 변경되지 않는다. (cf, splice는 원본 배열을 변경)
arr.slice(start, end);
// start: 복사를 시작할 인덱스. 음수인 경우에는 배열의 끝에서의 인덱스를 나타냄.
// slice(-2)는 배열의 마지막 두 개의 요소를 복사하여 배열로 반환.
// end: 복사를 종료할 인덱스. 이 인덱스에 해당하는 요소는 복사되지 않는다.
// end는 생략 가능. end 생략 시 기본값은 length 프로퍼티 값이다.
const arr = [1, 2, 3];
let result = arr.slice(0, 1);
console.log(result); // [ 1 ]
result = arr.slice(1, 2); // start부터 end이전까지이다. 따라서 2인덱스는 포함되지 않는다.
console.log(result); // [ 2 ]
console.log(arr); // [ 1, 2, 3 ] , 원본 배열이 변경되지 않음을 알 수 있다.
result = arr.slice(1); // start부터 끝까지이다.
console.log(result); // [ 2, 3 ]
result = arr.slice(-1); // 뒤에서 첫번쨰꺼
console.log(result); // [ 3 ]
result = arr.slice(-2); // 뒤에서 두번째꺼 까지이다.
console.log(result); // [ 2, 3 ]
result = arr.slice(); // 인수를 생략하면 배열을 복사한다
result[1] = 4;
console.log(arr); // [ 1, 2, 3 ]
console.log(result); // [ 1, 4, 3 ]
- 객체의 얕은 복사: 객체를 프로퍼티 값으로 갖는 객체의 경우 한 단계까지만 복사하는 것. 객체의 깊은 복사: 객체에 중첩되어 있는 개체까지 모두 복사하는 것.
- slice 메서드 , 스프레드 문법, Object.assign 메서드는 모두 얕은 복사를 수행.
2.10 Array.prototype.join
- 원본 배열의 모든 요소를 문자열로 변환한 후, 인수로 전달받은 문자열, 즉 구분자(seperator)로 연결한 문자열을 반환.
- 구분자는 생략가능. 기본 구분자는 컴마( , )이다.
const arr = [1, 2, 3, 4];
console.log(arr.join()); // 1,2,3,4
console.log(arr.join(" ")); // 1 2 3 4
console.log(arr.join(":")); // 1:2:3:4
2.11 Array.prototype.reverse
- 원본 배열의 순서를 반대로 뒤집음.
- 이때 원본 배열이 변경됨. 반환값은 변경된 배열.
const arr = [1, 2, 3];
const result = arr.reverse();
//원본 배열을 직접 변경한다.
console.log(arr); // [ 3, 2, 1 ]
console.log(result); // [ 3, 2, 1 ]
2.12 Array.prototype.fill
- 인수로 전달받은 값을 배열의 처음부터 끝까지 요소로 채움.
- 원본 배열이 변경된다.
arr.file(value, start, end);
// value를 start부터 end까지 채운다. 단, end는 포함하지 않는다.
const arr = [1, 2, 3];
arr.fill(0);
//fill 메서드는 원본 배열을 직접 변경한다.
console.log(arr); // [ 0, 0, 0 ]
//두번째 인수로 요소 채우기를 시작할 인덱스를 전달할 수 있다.
arr.fill(1, 1);
console.log(arr); // [ 0, 1, 1 ]
//세번째 인수로 요소 채우기를 끝낼 인자를 전달할 수 있다.
arr.fill(2, 1, 3);
console.log(arr); // [ 0, 2, 2 ]
2.13 Array.prototype.includes
- 배열 내에 특정 요소가 포함되어 있는 지 확인⇒ true또는 false를 반환
- 첫 번째 인수로 검색할 대상을 지정.
const arr = [1, 2, 3];
console.log(arr.includes(2)); // true
console.log(arr.includes(100)); // false
//두 번째 인자는 몇 번째부터 포함여부를 체크할 것인지
console.log(arr.includes(2, 1)); // true
//두번째 인자에 음수값이 오면 length - 음수값 부터 check를 시작한다.
console.log(arr.includes(1, -3)); // true
- indexOf 사용시에는 배열에서 NaN을 찾을 수 없다.
- 반면 includes는 NaN(string등 숫자가 아닌것들)을 배열에서 찾을 수 있다.
2.14 Array.prototype.flat
- ES10(ECMAScript 2019)에서 도입
- 인수로 전달한 깊이만큼 재귀적으로 배열을 평탄화
const arr = [1, [2, [3, [4]]]];
let result = arr.flat();
//원본은 바뀌지 않는다.
console.log(arr); // [ 1, [ 2, [ 3, [Array] ] ] ]
console.log(result); // [ 1, 2, [ 3, [ 4 ] ] ]
//2단계 적용
result = arr.flat(2);
console.log(result); // [ 1, 2, 3, [ 4 ] ]
//3단계 적용
result = arr.flat(3);
console.log(result); // [ 1, 2, 3, 4 ]
3. 고차함수
- 고차함수: 함수를 인수로 전달받거나 함수를 반환하는 함수. 외부 상태의 변경이나 가변 데이터를 피하고 불변성을 지향하는 함수형 프로그래밍에 기반을 두고 있다.
- 함수형 프로그래밍: 순수함수와 보조 함수의 조합을 통해 로직 내에 존재하는 조건문과 반복문을 제거하여 복잡성을 해결하고 변수의 사용을 억제하여 상태 변경을 피하려는 프로그래밍 패러다임. ⇒ 순수 함수를 통해 부수 효과를 최대한 억제하⇒ 오류를 피하고 + 프로그램의 안전성을 높이려는 것.
3.1. sort
- 배열의 요소를 정렬한다.
- 원본 배열을 직접 변경하여 정렬된 배열을 반환.
- 기본적으로 오름차순 정렬.
문자열 정렬
const fruits = ["Banana", "Orange", "Apple"];
fruits.sort();
console.log(fruits); // ['Apple', 'Banana', 'Orange']
const fruits = ["바나나", "오렌지", "사과"];
// 한글 문자열인 요소도 오름차순으로 정렬.
fruits.sort();
console.log(fruits); // ['바나나', '사과', '오렌지']
const fruits = ["Banana", "Orange", "Apple"];
// 오름차순(ascending) 정렬
fruits.sort();
// 내림차순
fruits.reverse(); // reverse 메서드도 원본 배열을 직접 변경한다.
console.log(fruits); // ['Orange', 'Banana', 'Apple']
숫자 정렬
const points = [40, 100, 1, 5, 2, 25, 10];
points.sort();
// 숫자 요소들로 이루어진 배열은 의도한 대로 정렬되지 않는다.console.log(points);// [1, 10, 100, 2, 25, 40, 5]
- sort 메서드는 유니코드 코드 포인트의 순서를 따라 정렬
- 숫자의 크기 ≠ 유니코드 순서 ⇒ 의도하는 대로 정렬되지 않을 수.
- sort 메서드는 배열의 요소를 일시적으로 문자열로 변환한 후 정렬.
["2", "1"].sort(); // -> ["1", "2"]
[2, 1].sort(); // -> [1, 2]
["2", "10"].sort(); // -> ["10", "2"]
[2, 10].sort(); // -> [10, 2]
⇒ 숫자 요소를 정렬할 때는 sort 메서드에 정렬 순서를 정의하는 비교 함수를 인수로 전달해야 한다. 비교 함수는 양수나 음수 또는 0을 반환해야 한다.
- 비교 함수 반환 값 < 0 : 첫 번째 인수를 우선 정렬
- 비교 함수 반환 값 = 0 : 정렬하지 않음
- 비교 함수 반환 값 > 0 : 두 번째 인수를 우선 정렬
const points = [40, 100, 1, 5, 2, 25, 10];
// 숫자 배열의 오름차순 정렬. 비교 함수의 반환값이 0보다 작으면 a를 우선하여 정렬한다.
points.sort((a, b) => a - b);
console.log(points); // [1, 2, 5, 10, 25, 40, 100]// 숫자 배열에서 최소/최대값 취득console.log(points[0], points[points.length]);// 1// 숫자 배열의 내림차순 정렬. 비교 함수의 반환값이 0보다 작으면 b를 우선하여 정렬한다.
points.sort((a, b) => b - a);
console.log(points); // [100, 40, 25, 10, 5, 2, 1]// 숫자 배열에서 최대값 취득console.log(points[0]);// 100
객체를 요소로 갖는 배열 정렬
- 비교 함수. 매개변수 key는 프로퍼티 키다프로퍼티 값이 문자열인 경우??
산술 연산으로 비교하면 NaN이 나오므로 비교 연산을 사용. - 비교 함수는 양수/음수/0을 반환하면 되므로 - 산술 연산 대신 비교 연산을 사용할 수 있다.
const todos = [
{ id: 4, content: "JavaScript" },
{ id: 1, content: "HTML" },
{ id: 2, content: "CSS" },
];
function compare(key) {
return (a, b) => (a[key] > b[key] ? 1 : a[key] < b[key] ? -1 : 0);
}
// id를 기준으로 오름차순 정렬
todos.sort(compare("id"));
console.log(todos);
/*
[
{ id: 1, content: 'HTML' },
{ id: 2, content: 'CSS' },
{ id: 4, content: 'JavaScript' }
]
*/
// content를 기준으로 오름차순 정렬
todos.sort(compare("content"));
console.log(todos);
/*
[
{ id: 2, content: 'CSS' },
{ id: 1, content: 'HTML' },
{ id: 4, content: 'JavaScript' }
]
*/
2. forEach
- for 문을 대체할 수 있는 고차 함수
- forEach 메서드는 자신의 내부에서 반복문을 실행
- 내부에서 반복문을 통해 자신을 호출한 배열을 순회⇒수행해야 할 처리를 콜백 함수로 전달받아 반복 호출
//for문
const numbers = [1, 2, 3];
let pows = [];
// for 문으로 배열 순회
for (let i = 0; i < numbers.length; i++) {
pows.push(numbers[i] ** 2);
}
console.log(pows); // [1, 4, 9]
//forEach문
const numbers = [1, 2, 3];
let pows = [];
// forEach 메서드는 numbers 배열의 모든 요소를 순회하면서 콜백 함수를 반복 호출.
numbers.forEach((item) => pows.push(item ** 2));
console.log(pows); // [1, 4, 9]
// forEach 메서드는 콜백 함수를 호출하면서 3개(요소값, 인덱스, this)의 인수를 전달한다.
[1, 2, 3].forEach((item, index, arr) => {
console.log(
`요소값: ${item}, 인덱스: ${index}, this: ${JSON.stringify(arr)}`
);
});
/*
요소값: 1, 인덱스: 0, this: [1,2,3]
요소값: 2, 인덱스: 1, this: [1,2,3]
요소값: 3, 인덱스: 2, this: [1,2,3]
*/
- forEach 메서드는 원본 배열을(return한 내용으로) 변경하지 않는다. ( 다만, 콜백 함수의 this를 통해 원본 배열을 변경할 수 있다.)
const numbers = [1, 2, 3];
// forEach 메서드는 원본 배열을 변경하지 않지만
// 콜백 함수를 통해 원본 배열을 변경할 수는 있다.
// 콜백 함수의 세 번째 매개변수 arr은 원본 배열 numbers를 가리킨다.
// 따라서 콜백 함수의 세 번째 매개변수 arr을 직접 변경하면 원본 배열 numbers가 변경된다.
numbers.forEach((item, index, arr) => {
arr[index] = item ** 2;
});
console.log(numbers); // [1, 4, 9]
- forEach 메서드의 반환값: 언제나 undefined
const result = [1, 2, 3].forEach(console.log);
console.log(result); // undefined
- for문과 달리 순회를 중간에 중단할 수 없고, 배열의 모든 요소를 빠짐업이 순회.
- 희소 배열의 경우 존재하지 않는 요소는 순회 대상에서 제외됨.
// 희소 배열const arr = [1, , 3];
// for 문으로 희소 배열을 순회
for (let i = 0; i < arr.length; i++) {
console.log(arr[i]); // 1, undefined, 3
}
// forEach 메서드는 희소 배열의 존재하지 않는 요소를 순회 대상에서 제외.
arr.forEach((v) => console.log(v)); // 1, 3
3. map
- 자신을 호출한 배열의 모든 요소를 순회하면서 인수로 전달받은 콜백 함수를 반복 호출 ⇒ 콜백 함수의 반환값들로 구성된 새로운 배열을 반환. === 원본 배열 변경 X
const numbers = [1, 4, 9];
const roots = numbers.map((item) => Math.sqrt(item));
//map 메서드는 새로운 배열을 반환한다
console.log(roots); // [ 1, 2, 3 ]
// map 메서드는 원본 배열을 변경하지 않는다
console.log(numbers); // [ 1, 4, 9 ]
- forEach 메서드: 단순히 반복문을 대체하기 위한 고차 함수
- map 메서드: 요소값을 다른 값으로 매핑한 새로운 배열은 생성하기 위한 고차 함수. 1:1 매핑.

// map 메서드는 콜백 함수를 호출하면서 3개(요소값, 인덱스, this)의 인수를 전달한다.
[1, 2, 3].map((item, index, arr) => {
console.log(
`요소값: ${item}, 인덱스: ${index}, this: ${JSON.stringify(arr)}`
);
return item;
});
/*
요소값: 1, 인덱스: 0, this: [1,2,3]
요소값: 2, 인덱스: 1, this: [1,2,3]
요소값: 3, 인덱스: 2, this: [1,2,3]
*/
4. filter
- 자신을 호출한 배열의 모든 요소를 순회하면서 인수로 전달받은 콜백 함수를 반복 호출 ⇒ 콜백 함수의 반환 값이 true인 요소로만 구성된 새로운 배열을 반환 === 원본 배열을 변경되지 않는다.
const numbers = [1, 2, 3, 4, 5];
// 다음의 경우 numbers 배열에서 홀수인 요소만을 필터링한다(1은 true로 평가).
const odds = numbers.filter((item) => item % 2);
console.log(odds); // [1, 3, 5]
- 자신을 호출한 배열에서 필터링 조건을 만족하는 특정 요소만 추출하여 새로운 배열을 만들고 싶을 때 사용

- 자신을 호출한 배열에서 특정 요소를 제거하기 위해 사용.
class Users {
constructor() {
this.users = [
{ id: 1, name: "Lee" },
{ id: 2, name: "Kim" },
];
}
// 요소 추출
findById(id) {
return this.users.filter((user) => user.id === id);
// id가 일치하는 사용자만 반환
}
// 요소 제거
remove(id) {
this.users = this.users.filter((user) => user.id !== id);
// id가 일치하지 않는 사용자를 제거
}
}
const users = new Users();
let user = users.findById(1);
console.log(user); // [{ id: 1, name: 'Lee' }]
// id가 1인 사용자를 제거한다.
users.remove(1);
user = users.findById(1);
console.log(user); // []
5. reduce
- 자신을 호출한 배열을 모든 요소를 순회하면 인수로 전달받은 콜백 함수를 반복 호출 ⇒ 콜백 함수의 반환 값을 다음 순회 시에 콜백 함수의 첫 번째 인수로 전달하면서 콜백 함수를 호출하여 하나의 결과값을 만들어 반환한다.
- 첫 번째 인수로 콜백함수, 두 번째 인수로 초기값을 전달 받는다.
- 콜백 함수에는 초기값 또는 콜백 함수의 이전 반환 값, reduce 메서드를 호출한 배열의 요소값, 인덱스, reduce 메서드를 호출한 메서드(this)가 인수로 전달된다.
// [1, 2, 3, 4]의 모든 요소의 누적을 구한다.
const sum = [1, 2, 3, 4].reduce(
(accumulator, currentValue, index, array) => accumulator + currentValue,
0
);
console.log(sum); // 10
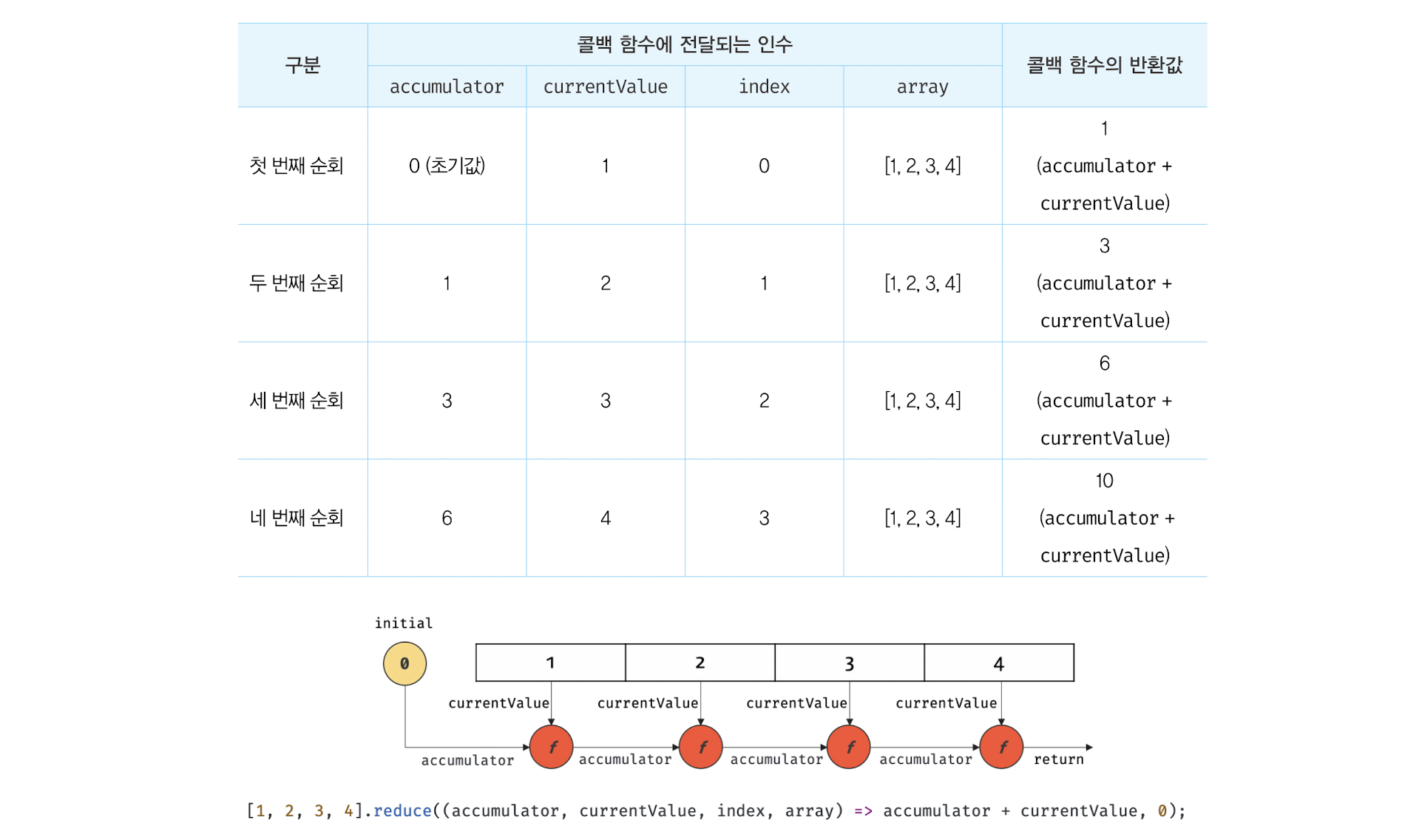
- 초기값과 배열의 첫 번째 요소값을 콜백 함수에게 인수로 전달하면서 호출하고 다음 순회에는 콜백 함수의 반환값과 두 번째 요소값을 콜백 함수의 인수로 전달하면서 호출. 이러한 과정을 반복하여 reduce 메서드는 하나의 결과값을 반환한다.
1) 평균 구하기
const values = [1, 2, 3, 4, 5, 6];
const average = values.reduce((acc, cur, i, { length }) => {
// 마지막 순회가 아니면 누적값을 반환하고 마지막 순회면 누적값으로 평균을 구해 반환.
return i === length - 1 ? (acc + cur) / length : acc + cur;
}, 0);
console.log(average); // 3.5
2) 최대값 구하기 : Math.max 메서드 사용이 더 직관적
const values = [1, 2, 3, 4, 5];
const max = values.reduce((acc, cur) => (acc > cur ? acc : cur), 0);
console.log(max); // 5
const max = Math.max(...value);
console.log(max); // 5
3) 요소의 중복 횟수 구하기
const fruits = ['banana', 'apple', 'orange', 'orange', 'apple'];
const count = fruits.reduce((acc, cur) => {
// 첫 번째 순회 시 acc는 초기값인 {}이고 cur은 첫 번째 요소인 'banana'다.
// 초기값으로 전달받은 빈 객체에 요소값인 cur을 프로퍼티 키로, 요소의 개수를 프로퍼티 값으로
// 할당한다. 만약 프로퍼티 값이 undefined(처음 등장하는 요소)이면 프로퍼티 값을 1로 초기화한다.
acc[cur] = (acc[cur] || 0) + 1;
return acc;
}, {});
// 콜백 함수는 총 5번 호출되고 다음과 같이 결과값을 반환한다./*
{banana: 1} => {banana: 1, apple: 1} => {banana: 1, apple: 1, orange: 1}
=> {banana: 1, apple: 1, orange: 2} => {banana: 1, apple: 2, orange: 2}
*/console.log(count);// { banana: 1, apple: 2, orange: 2 }
4) 중복 요소 제거 : filter 메서드 사용이 더 직관적
또는 중복되지 않은 유일한 값들의 집합인 Set 사용
const values = [1, 2, 1, 3, 5, 4, 5, 3, 4, 4];
const result = values.reduce(
(unique, val, i, _values) =>
// 현재 순회 중인 요소의 인덱스 i가 val의 인덱스와 같다면 val은 처음 순회하는 요소다.// 현재 순회 중인 요소의 인덱스 i가 val의 인덱스와 다르다면 val은 중복된 요소다.// 처음 순회하는 요소만 초기값 []가 전달된 unique 배열에 담아 반환하면 중복된 요소는 제거된다.
_values.indexOf(val) === i ? [...unique, val] : unique,
[]
);
console.log(result); // [1, 2, 3, 5, 4]
5) 중첩배열 평탄화: flat 메서드 사용이 더 직관적
초기값
- reduce 메서드의 초기값은 옵션 값이지만 넣는것이 안전.
// reduce 메서드의 두 번째 인수, 즉 초기값을 생략했다.const sum = [1, 2, 3, 4].reduce((acc, cur) => acc + cur);
console.log(sum); // 10
const sum = [].reduce((acc, cur) => acc + cur);
// TypeError: Reduce of empty array with no initial value
const sum = [].reduce((acc, cur) => acc + cur, 0);
console.log(sum); // 0
- 객체의 특정 프로퍼티 값을 합산하는 경우에는 반드시 초기값을 전달.
const products = [
{ id: 1, price: 100 },
{ id: 2, price: 200 },
{ id: 3, price: 300 },
];
// 1번째 순회 시 acc는 { id: 1, price: 100 }, cur은 { id: 2, price: 200 }이고
// 2번째 순회 시 acc는 300, cur은 { id: 3, price: 300 }이다.
// 2번째 순회 시 acc에 함수에 객체가 아닌 숫자값이 전달된다. 이때 acc.price는 undefined다.
const priceSum = products.reduce((acc, cur) => acc.price + cur.price);
console.log(priceSum); // NaN
const products = [
{ id: 1, price: 100 },
{ id: 2, price: 200 },
{ id: 3, price: 300 },
];
/*
1번째 순회 : acc => 0, cur => { id: 1, price: 100 }
2번째 순회 : acc => 100, cur => { id: 2, price: 200 }
3번째 순회 : acc => 300, cur => { id: 3, price: 300 }
*/ const priceSum = products.reduce((acc, cur) => acc + cur.price, 0);
console.log(priceSum); // 600
6. some
- 자신을 호출한 배열의 요소를 순회하면서 인수로 전달된 콜백 함수를 호출
- 이때 some 메서드는 콜백 함수의 반환값이 단 한번이라도 참이면 true, 모두 거짓이면 false를 반환 ⇒ 배열의 요소 중에 콜백 함수를 통해 정의한 조건을 만족하는 요소가 1개 이상 존재하는지 확인하여 그 결과를 Boolean 타입으로 반환(ture/false).
// 배열의 요소 중에 10보다 큰 요소가 1개 이상 존재하는지 확인
[5, 10, 15].some((item) => item > 10); // -> true
// 배열의 요소 중에 0보다 작은 요소가 1개 이상 존재하는지 확인
[5, 10, 15].some((item) => item < 0); // -> false
// 배열의 요소 중에 'banana'가 1개 이상 존재하는지 확인
["apple", "banana", "mango"].some((item) => item === "banana"); // -> true
// some 메서드를 호출한 배열이 빈 배열인 경우 언제나 false를 반환.
[].some((item) => item > 3); // -> false
7. every
- 자신을 호출한 배열의 요소를 순회하면서 인수로 전달된 콜백 함수를 호출
- 콜백 함수의 반환값이 모두 참이면 ture, 단 한번이라도 거짓이면 false를 반환 ⇒ 즉, 배열의 모든 요소가 콜백 함수를 통해 정의한 조건을 모두 만족하는지 확인하여 그 결과를 Boolean 타입으로 반환(ture/false).
// 배열의 모든 요소가 3보다 큰지 확인
[5, 10, 15].every((item) => item > 3); // -> true
// 배열의 모든 요소가 10보다 큰지 확인
[5, 10, 15].every((item) => item > 10); // -> false
// every 메서드를 호출한 배열이 빈 배열인 경우 언제나 true를 반환한다.
[].every((item) => item > 3); // -> true
8. find
- ES6에서 도입된
- 자신을 호출한 배열의 요소를 순회하면서 인수로 전달된 콜백 함수를 호출하여 반환값이 true인 첫 번째 요소를 반환. 만약 콜백 함수의 반환값이 true인 요소가 존재하지 않는다면 undefined를 반환한다.
const users = [
{ id: 1, name: "Lee" },
{ id: 2, name: "Kim" },
{ id: 2, name: "Choi" },
{ id: 3, name: "Park" },
];
// id가 2인 첫 번째 요소를 반환한다. find 메서드는 ~~배열~~이 아니라 요소를 반환한다.
users.find((user) => user.id === 2); // -> {id: 2, name: 'Kim'}
9. findIndex
- ES6에 도입
- 자신을 호출한 배열의 요소를 순회하면서 인수로 전달된 콜백 함수를 호출하여 반환값이 true인 첫 번째 요소의 인덱스를 반환한다.
const users = [
{ id: 1, name: "Lee" },
{ id: 2, name: "Kim" },
{ id: 2, name: "Choi" },
{ id: 3, name: "Park" },
];
// id가 2인 요소의 인덱스를 구한다.
users.findIndex((user) => user.id === 2); // -> 1
// name이 'Park'인 요소의 인덱스를 구한다.
users.findIndex((user) => user.name === "Park"); // -> 3
// 위와 같이 프로퍼티 키와 프로퍼티 값으로 요소의 인덱스를 구하는 경우
// 다음과 같이 콜백 함수를 추상화할 수 있다.
function predicate(key, value) {
// key와 value를 기억하는 클로저를 반환
return (item) => item[key] === value;
}
// id가 2인 요소의 인덱스를 구한다.
users.findIndex(predicate("id", 2)); // -> 1
// name이 'Park'인 요소의 인덱스를 구한다.
users.findIndex(predicate("name", "Park")); // -> 3
10. flatMap
- ES10에서 도입
- map 메서드를 통해 생성된 새로운 배열을 평탄화한다. map 메서드와 flat 메서드를 순차적으로 실행하는 효과
const arr = ["hello", "world"];
// map과 flat을 순차적으로 실행
arr.map((x) => x.split("")).flat();
// -> ['h', 'e', 'l', 'l', 'o', 'w', 'o', 'r', 'l', 'd']
// flatMap은 map을 통해 생성된 새로운 배열을 평탄화한다.
arr.flatMap((x) => x.split(""));
// -> ['h', 'e', 'l', 'l', 'o', 'w', 'o', 'r', 'l', 'd']
- flat 메서드 처럼 평탄화 깊이를 지정할 수는 없고, 1단계만 평탄화한다.
⇒ 평탄화 깊이를 지정해야 하면 map 메서드와 flat 메서드를 각각 호출.
const arr = ["hello", "world"];
// flatMap은 1단계만 평탄화한다.
arr.flatMap((str, index) => [index, [str, str.length]]);
// -> [[0, ['hello', 5]], [1, ['world', 5]]] => [0, ['hello', 5], 1, ['world', 5]]
// flat은 평탄화 깊이 지정 가능
arr.map((str, index) => [index, [str, str.length]]).flat(2);
// -> [[0, ['hello', 5]], [1, ['world', 5]]] => [0, 'hello', 5, 1, 'world', 5]